
Содержание

Наряду с новым графическим процессором Mali-G77 и процессором отображения Mali-D77, Arm представила свой новейший высокопроизводительный процессор - Cortex-A77. Как и в прошлом году Cortex-A76, Cortex-A77 предназначен для приложений премиум-уровня, требующих фирменного низкого энергопотребления Arm. Все от смартфонов до ноутбуков и, скорее всего, за его пределами.
С Cortex-A77 Arm нацелена на максимальное увеличение производительности команд / тактов / тактов (IPC), которое оно может справиться с Cortex-A76. Тактовые частоты, энергопотребление и площадь рассчитаны на то, чтобы оставаться примерно на одном уровне, но новое ядро может обрабатывать больше команд за один раз. Чтобы сделать это, Arm разработала еще более широкое ядро, чем в прошлом году, и внесла ряд улучшений, чтобы ядро ЦП работало. Но прежде чем мы перейдем к этому, давайте углубимся в обзор высокого уровня и показатели производительности.
Удар по производительности
Еще в августе 2018 года Arm нехарактерно поделилась «дорожной картой» ЦП до 2020 года. С Cortex-A73 2016 года до дизайна Hercules до 2020 года компания обещает 2,5-кратное увеличение производительности вычислений. Большая часть этой огромной проекции была достигнута благодаря основному сдвигу микроархитектуры с Cortex-A76, более высоким современным тактовым частотам и переходу с 16 на 10, а теперь и 7-нм производства с 5-нм последующим. Около 1,8x результатов дорожной карты уже были достигнуты в прошлом году, а Cortex-A77 обеспечивает увеличение IPC примерно на 20 процентов. Это дает нам хороший путь к достижению 2,5-кратной цели Arm, хотя мобильные устройства с ограниченным энергопотреблением и тепловым бюджетом не ожидают увидеть все эти выгоды.
Для сравнения, прошлогодний Cortex-A76 обеспечил прирост на 30-35 процентов по сравнению с Cortex-A75. В этом году мы рассматриваем более приглушенный, но все же значительный 20-процентный прирост IPC между A77 и A76. Это хорошая новость, потому что это означает повышение производительности при соблюдении тех же ограничений по температуре и мощности, что и раньше. Компромисс в том, что A77 примерно на 17 процентов больше, чем A76, поэтому будет стоить немного дороже с точки зрения площади кремния. Если вы хотите сравнить с лидерами настольных систем, AMD удалось увеличить IPC на 15 процентов между Zen2 и Zen +, в то время как IPC от Intel оставалась практически неизменной в течение многих лет.Конечно, мы говорим здесь о различных сегментах рынка, но это демонстрирует, как команда разработчиков процессоров Arm добилась впечатляющих успехов в последние поколения.
Повышение производительности на 20% предлагается для SoC нового поколения на базе Cortex-A77
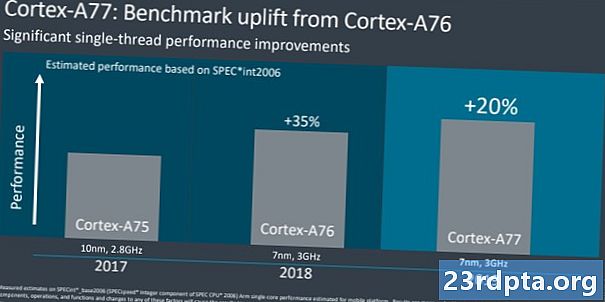
Вывод здесь заключается в том, что A76 ознаменовал собой значительный микроархитектурный сдвиг с огромным приростом производительности, в то время как мы вернулись к повышению уровня оптимизации с A77. С этим из пути давайте погрузимся в то, что нового в Arm Cortex-A77.
Cortex-A77 построен на микроархитектуре A76
Ключом к пониманию разницы между Cortex-A77 и A76 является понимание того, что подразумевается под «более широкой» базовой конструкцией. По сути, речь идет о возможности выполнять больше инструкций для каждого тактового цикла, что увеличивает пропускную способность ядра. Чтобы сделать это правильно, есть две важные части: увеличение количества исполнительных блоков, выполняющих обработку, и обеспечение того, чтобы эти блоки хорошо снабжались данными. Давайте начнем с последней части и сосредоточимся на частях SoC, связанных с диспетчеризацией, кэшем и ветвлением.
Cortex-A77 видит 50-процентное увеличение ширины диспетчеризации, до шести инструкций за цикл из четырех с A76. Это означает, что для каждого тактового цикла для большего потенциала производительности направляется больше инструкций к ядру выполнения. В результате окно выполнения не по порядку также становится больше, увеличиваясь до 160 записей, чтобы обеспечить больше параллелизма. Имеется привычный кэш команд размером 64 КБ, в то время как целевой буфер ветвления (BTB), который содержит адреса для предиктора ветвления, на 33% больше, чем раньше, для обработки роста параллельных инструкций. Ничего необычного здесь нет, это по сути более широкая версия прошлогоднего дизайна.
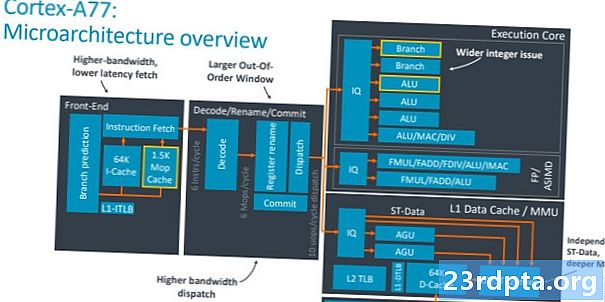
Более интригующим дополнением внешнего интерфейса является полностью новый кэш MOP 1,5 КБ, в котором хранятся макрооперации (MOP), которые возвращаются обратно из модуля декодирования. Архитектура процессора Arm декодирует инструкции из пользовательского приложения в более мелкие макрооперации, а затем углубляется в микрооперации, которые понимает ядро выполнения. Вы можете увидеть это на диаграмме выше в разделе декодирования. Кэш MOP используется для уменьшения потери стоимости пропущенных ветвлений и сбросов, поскольку вы держите макро-операции вместо их повторного декодирования и увеличиваете общую пропускную способность ядра. Выборки из MOP вместо i-cache обходят этап декодирования, сохраняя один цикл. Арм заявляет, что кэш MOP может достигать 85% или более коэффициентов попадания в диапазоне рабочих нагрузок, что делает его очень полезным дополнением к стандартному i-кешу.
Переходя к части ядра процессора, обратите внимание на добавление четвертого ALU и второго блока Branch. Этот четвертый ALU увеличивает общую пропускную способность процессора на 50%. Этот дополнительный ALU способен выполнять основные одноцикловые инструкции (такие как ADD и SUB) плюс двухтактные целочисленные операции, такие как умножение. Два из других ALU могут обрабатывать только базовые однотактные инструкции, в то время как последний блок загружается более сложными математическими операциями, такими как деление, умножение, накопление и т. Д. Второй блок ветвления внутри ядра выполнения удваивает количество одновременных переходов ветвлений. Ядро может справиться, что полезно в случаях, когда две из шести отправленных команд являются переходами ветви. Это звучит немного странно, но внутреннее тестирование в Arm показало выигрыш в производительности от использования этого второго устройства.
Cortex-A77 предлагает улучшенный параллелизм и новый подход к кэшам предварительной выборки
Другие изменения в ядре процессора включают добавление второго конвейера шифрования AES. Конвейеры хранилища данных теперь имеют выделенные порты выдачи для удвоения пропускной способности памяти. Эти порты ранее использовались совместно с ALU, что иногда могло стать узким местом. Также имеется усовершенствованный механизм передачи данных следующего поколения, позволяющий повысить эффективность энергопотребления и одновременно увеличить пропускную способность системы DRAM.
Часть этой системы в Cortex-A77 также оснащена совершенно новой системой предварительной выборки, ориентированной на систему. Это повышает производительность памяти на основе широкого диапазона количества ядер ЦП, емкости и задержек кэш-памяти, а также конфигураций подсистем памяти внутри конечных устройств. Выделенное оборудование для связи с модулем динамического планирования (DSU) в составе кластера ЦП DynamIQ, который отслеживает использование общего кэша L3. Ядро имеет динамическое расстояние и уровни агрессивности для уменьшения использования кэша в ситуациях, когда пропускная способность L3 ограничена другими ядрами ЦП. Ядра с более высокой производительностью, такие как Cortex-A77, с большей вероятностью насыщают доступ DSU к памяти, в то время как ядра с меньшим энергопотреблением, такие как A55, вряд ли.

Соединяя все это вместе
В Cortex-A77 есть множество небольших изменений, которые дополняют некоторые существенные отличия от его предшественника. Короче говоря, новый кэш MOP A77 в сочетании с более широким и длинным окном инструкций помогает поддерживать занятые модули ALU, Branch и модули памяти занятыми делами. Мощная конструкция Cortex-A76 была расширена, чтобы еще больше повысить ее пропускную способность с A77, не полагаясь на более высокие тактовые частоты.
Наибольший прирост производительности достигается в Cortex-A77 в виде целочисленной математики и математики с плавающей запятой. Это подтверждается внутренними тестами Arm, которые демонстрируют повышение производительности на 20–35 процентов в целочисленных и плавающих тестах SPEC соответственно. Улучшения пропускной способности памяти находятся где-то между 15 и 20 процентами, что еще раз подчеркивает, что наибольший выигрыш приходит в виде сокращения числа. В целом, эти улучшения дают A77 в среднем 20-процентное повышение по сравнению с предыдущим поколением. Мы также можем увидеть некоторые дальнейшие, более незначительные выгоды в результате более совершенных 7-нм производственных процессов в конце этого года или в начале 2020 года.
С точки зрения смартфонов, SoC с питанием от Cortex-A77 предназначены для высокопроизводительных флагманских продуктов. Arm полностью ожидает, что конструкция электростанции будет использовать 4 + 4 бит. Учитывая увеличенную пропускную способность и небольшой удар по размеру области A77, мы, вероятно, увидим, что дизайнеры SoC продолжат снижаться в направлении 1 + 3 + 4 или 2 + 2 + 4. С одним или двумя мощными большими ядрами с большими кэшами и более высокими тактовыми частотами, резервное копирование с 2 или 3 ядрами A77 с меньшими размерами кэша и меньшими тактовыми частотами для экономии энергии и площади. В конечном счете, Cortex-A77 - это отличная вещь для чипов смартфонов и растущего рынка постоянно подключенных ноутбуков на базе Arm. Следите за объявлениями кремния позже в этом году.


